
데이터 모델링
논리적 모델링, 물리적 모델링
논리적 모델링은 테이블의 구조를 정해나가는 모델링이고, 물리적 모델링은 데이터베이스를 실제로 구축하는 데 필요한 내용들을 정해나가는 모델링이다.
데이터 모델
- Entity(개체) 데이터를 저장하려고 하는 대상(테이블)
- Attribute(속성) Entity에 대해서 저장하려고 하는 특징(컬럼)
- Relationship(관계) Entity들 사이 생기는 연결점
- Constraint(제약 조건) 여러 데이터 요소들에 있는 규칙
데이터 모델링
데이터 모델의 요소들을 파악한 후, 이 내용들을 발전시켜 데이터 모델들을 만드는 과정.
Relational 모델
여기서 Relation은 테이블을 의미하는 수학적 표현이다.
데이터를 relation, 즉 테이블로 정리해서 표현한 모델을 말한다.
Entity는 테이블, attribute는 컬럼, relationship은 foreign key를 사용해서 정리하는 모형이다.
Entity Relationship Model(ERM)
모델링을 할 때는 로우에 대해선 신경을 쓰지 않기 때문에 릴레이셔널 모델과는 다른형태의 ERM모델을 같이 사용한다.
ERM은 로우를 매번 표현하지 않아도 된다.
데이터 모델 스펙트럼
개념 모델
가장 추상적인 모델이고, 대략적으로 Entity들과 Entity들 사이에 있는 관계 정도만 표현한다.
논리 모델
개념 모델보다는 좀 더 자세한 내용을 담는다. Entity들이 갖는 Attribute들과 primary key, Entity들 사이 관계를 표현할 foreign key, 이런 내용까지 표현한다.
물리 모델
DB를 실제로 구축할 때 필요한 내용에 최대한 가까운 내용을 담고 있는 모델이다.
논리적 모델링
비즈니스 룰
특정 조직이 운영되기 위해 따라야 하는 정책, 절차, 원칙에 대한 간단 명료한 설명을 말한다.
Entity, Relationship, Attribute 후보 찾기
- 모든 명사는 Entity후보다.
- 모든 동사는 Relationship후보다.
- 하나의 값으로 표현할 수 있는 명사는 Attribute의 후보다.
Attribute예외
하나의 값으로 표현할 수 있더라도 하나의 Entity가 여러 개의 값을 가져야하는 경우는 예외이며 Entity후보다.
| user | ||||
|---|---|---|---|---|
| name | address1 | address2 | address3 | |
| a@.. | 영희 | 서울 | 부산 | 수원 |
| b@.. | 철수 | 대구 | NULL | NULL |
이렇게 하게되면 NULL이 많이 생기고 컬럼의 개수가 유동적이고 조회가 비효율 적이게 된다.
이럴때는 새로운 테이블(Entity)로 만든다
| user | ||
|---|---|---|
| id | name | |
| 1 | a@.. | 영희 |
| 2 | b@.. | 철수 |
| address | ||
|---|---|---|
| id | user_id | address |
| 1 | 1 | 서울 |
| 2 | 1 | 부산 |
| 3 | 1 | 수원 |
| 4 | 2 | 대구 |
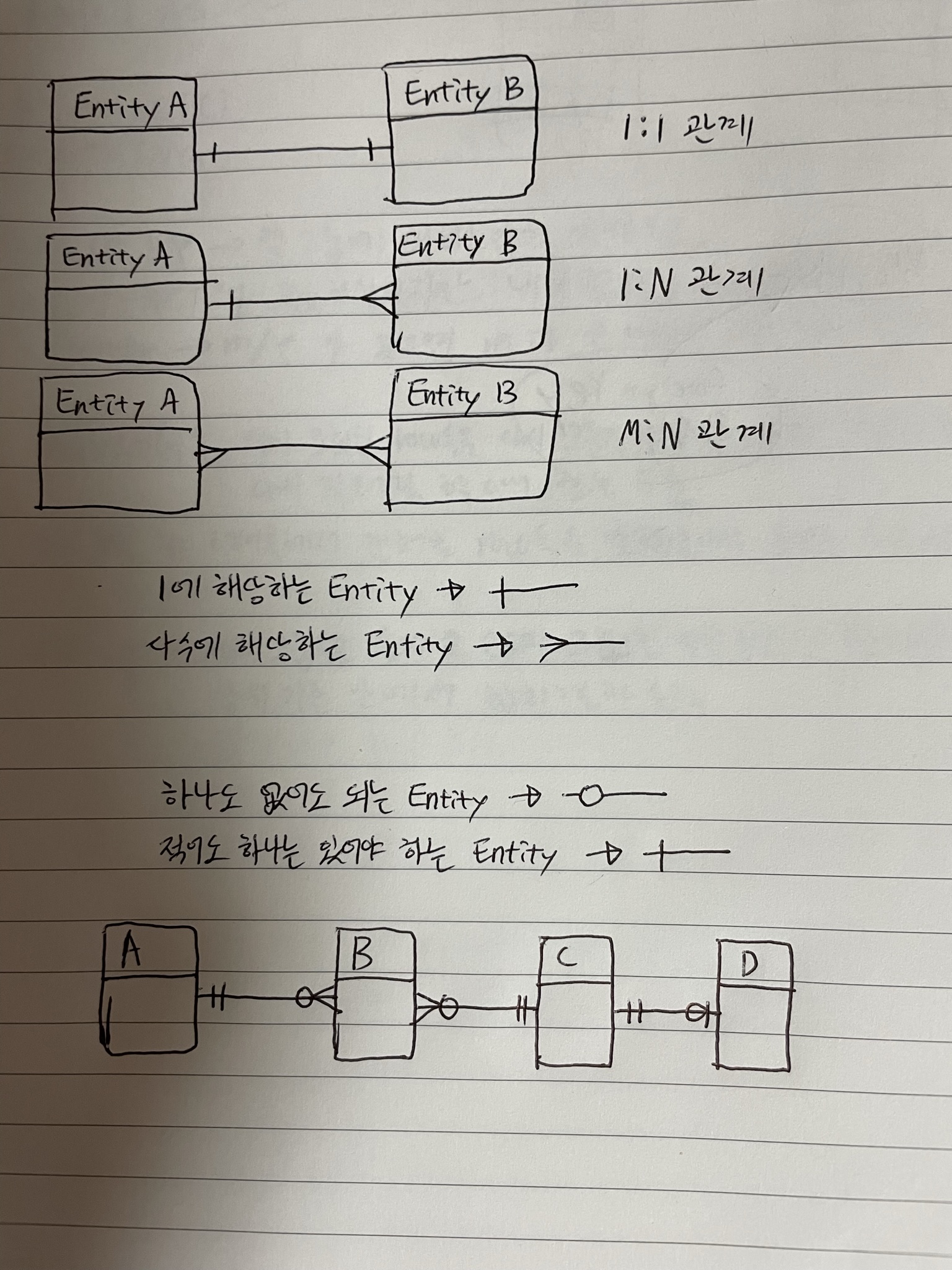
카디널리티
카디널리티는 두 entity type사이 관계에서 한 종류의 entity가 다른 종류의 entity 몇 개에 대해서 관계를 맺을 수 있는지 나타낸 개념이다.
이상 현상(anomaly)
삽입 이상
새로운 데이터를 자연스럽게 저장할 수 없는 경우
업데이트 이상
데이터를 업테이트했을 때 정확성을 지키기 어려워지는 경우
삭제 이상
원하는 데이터만 자연스럽게 삭제할 수 없는 경우
정규화(Normalization)
테이블을 정규형이라고 하는 형태에 부합하게 만들어 나가는 과정.
정규형(Normal From)
1NF,2NF…
순서에 따라 규칙이 누적된다.
1NF
테이블 안 모든 로우의 모든 컬럼 값들은 나눌 수 없는 단일 값이어야 한다.
- 한 컬럼에 같은 종류의 값을 여러 개 저장하고 있을 때
이때는 해당 컬럼을 하나의 테이블로 분리해서 모델링한다.
| id | name | |
|---|---|---|
| 1 | 영희 | a@…, b@… |
| 2 | 철수 | c@… |
이렇게 한 컬럼에 같은 종류의 값들이 여러 개 들어갈 때는 해당 컬럼을 분리해서 새로운 테이블로 만들고 부모 자식 관계를 만들면 된다.
- 한 컬럼에 서로 다른 종류의 값을 여러 개 저장하고 있을 때
이때는 한 컬럼을 여러 개로 분리해서 모델링한다.
| id | first_name | middle_name | last_name |
|---|---|---|---|
| 1 | Jack | Young | Adams |
함수 종속성
함수 종속성(Functional Dependency)은 x의 값에 따라서 y의 값이 결정될 때, y는 x에 함수 종속성이 있다고 한다. x -> y
| user | |||
|---|---|---|---|
| name | age | gender | |
| a@.. | 영희 | 20 | f |
email을 알면 나머지 값들을 알 수 있지만 age를 안다고 해서 다른 값들을 유추할 수 없다.
이때 name, age, gender는 email에 함수 종속성이 있다고 한다. email -> {name, age, gender}
두 가지 컬럼을 합쳐서 종속성을 가질 수도 있다. {A, B} -> C
이행성
A -> B -> C 이렇게 하나 이상의 Attribute를 거쳐서 함수 종속성이 있는 경우에 C는 A에 대해 이행정 함수 종속성이 있다라고 한다.
Candidate Key
Candidate Key는 하나의 로우를 특정 지을 수 있는 Attribute들의 최소 집합을 말한다.
| review | ||||
|---|---|---|---|---|
| id | user_id | product_id | score | description |
user_id와 product_id를 알면 하나의 로우를 특정할 수 있다. 이때 {user_id, product_id}를 Candidate Key라 한다. id도 Candidate Key다.
Candidate Key에 해당하는 모든 로우들을 prime attribute라 하고 그외에는 non-prime attribute라 한다.
2NF
테이블에 Candidate Key의 일부분에 대해서만 함수 종속성이 있는 non-prime attribute가 없어야 한다.
3NF
테이블 안에 있는 모든 Attribute들은 오직 Primary Key에 대해서만 함수 종속성이 있어야 한다. (테이블의 모든 Attribute는 직접적으로 테이블 Entity에 대한 내용이어야만 한다.)
물리적 모델링
- 이름 짓기
- 단수/복수 정하기
- 대문자/띄어쓰기 정하기
- 줄임말 정하기
- 데이터 타입 정하기
- 데이터 정확성을 지킬 수 있다.
- 데이터베이스 연산/함수들을 제대로 활용할 수 있다.
- 데이터베이스 용량을 최적화할 수 있다.
선형, 이진 탐색
선형탐색은은 앞에서 부터 순서대로 탐색
이진탐색은 정렬이 돼있다는 가정하에 절반씩 나눠 탐색
인덱스
특정 컬럼의 값들을 정렬해서 저장한 것을 인덱스라 한다.
Clustered 인덱스
테이블 자체를 특정 순서로 저장하는 인덱스.
- 조회 속도가 빠르다.
- 인덱스를 하나밖에 못 만든다.
한 컬럼을 기준으로 정렬해 놓고 또 다른 컬럼을 기준으로 동시에 정렬할 수 없다.
Non-Clustered 인덱스
테이블 자체는 그대로 놔두고 다른 곳에 순서를 저장.
- 인덱스를 모든 컬럼에 대해서 만들 수 있다.
- Clustered 인덱스보다는 조금 느리다.
- 책의 인덱스와 비슷한 개념.
인덱스 단점
- 인덱스 만큼 용량이 늘어난다.
- 하나의 로우 값을 바꾸면 해당 컬럼이 포함된 모든 인덱스를 수정해야 한다.
Leave a comment